1. 데이터는 kaggle(캐글)에 공개된 데이터를 썼습니다.
https://www.kaggle.com/datasets/joonasyoon/clustering-exercises/data

csv파일로 되어있으니 판다스로 읽어서 넘파이배열로 바꾸는 작업을 하겠습니다.
!wget https://www.kaggle.com/datasets/joonasyoon/clustering-exercises -O sample.npy
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
basic1=pd.read_csv('/content/basic1.csv')
basic1.head()
데이터를 잘 읽었다는 표시와 함께 판다스배열이 보이네요.
개인적으로 저는 kaggle(캐글) 데이터를 다운받아서 코랩에 파일을 올렸습니다.
추후 예측치와 비교하기 위해... 일단 판다스의 color부분을 target으로 빼 놨어요
target = basic1['color'].to_numpy() # 추후 예측치와 비교를 위한
basic1.drop('color', axis=1, inplace=True)
print(basic1)
print(target)코랩에서 코드를 넣으면, 결과가 이렇게 보여져요.
일단 판다스로 읽어드린 파일을 넘파이배열로 바꾸고
npbasic1 = basic1.to_numpy()
print(npbasic1)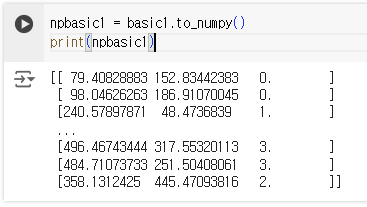
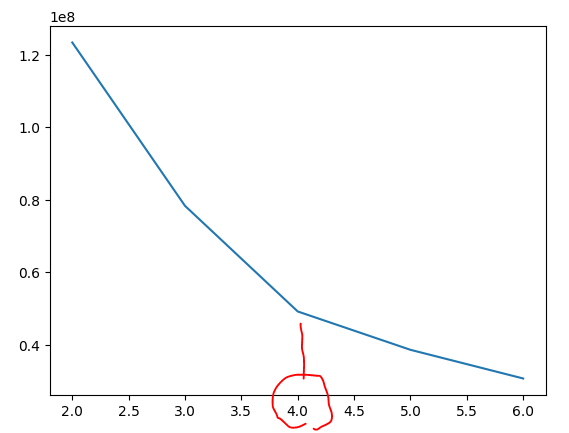
가장 중요한 것. 군집중심점의 갯수을 파악해볼까요?
# 적절한 군집중심점 갯수 파악(엘보우)
inertia = []
for k in range(2,7):
km = KMeans(n_clusters=k, random_state=42)
km.fit(npbasic1)
inertia.append(km.inertia_)
plt.plot(range(2,7), inertia)
plt.show()
4가 좋네요.
# KMeans를 이용해 군집화 실행-> 라벨개수 파악(labels)
km = KMeans(n_clusters=4, random_state=42)
km.fit(npbasic1)
# print(km.labels_)
print(np.unique(km.labels_, return_counts=True))
# 산점도로 각 군집의 분포도 나타내보기
fig, axs = plt.subplots(1, 2, figsize=(16,8))
axs[0].scatter(npbasic1[:, 0], npbasic1[:, 1], c=target)
axs[1].scatter(npbasic1[:, 0], npbasic1[:, 1], c=km.labels_)
# axs[0].set_title('Actual')
# axs[1].set_title('Machine')
'머신러닝' 카테고리의 다른 글
| 지니 불순도(Gini impurity)와 정보 이득 (0) | 2024.05.17 |
|---|---|
| 확률적 경사 하강법 (0) | 2024.05.16 |
| Sklearn(사이킷런) 붓꽃 데이터 (0) | 2024.05.13 |


